SfMで作成された巨大な点群の鳥瞰視点画像を作成する
車載のセンサーの観測情報つかってSfMをおこない環境地図を作成することがある。 この環境地図はかなり大きいサイズになり、点群は専用のViewerが必要になるため、他の人に気軽に共有して見てもらうみたいなことができないのが面倒だと思っている。 ここでは点群を俯瞰した状態を画像として作成し、その画像を他の人に共有することで解決できないかを考えた。
まず巨大な点群を描画するためのViewerはPotree, Open3D, pptkなどいくつか候補がある。 この中でOpen3Dが活発に開発されているので良いと考えた。pptkも良いのだが機能が最小限であり先々考えると不安がある。PotreeはOpen3Dを試して十分だと感じたので調べていない。
また、細かい要件だが、以下のようなことも求める
- 要件①点群の3次元の座標と得られた鳥瞰視点画像の画素の座標をあとから対応付けできること
- 要件②出力される鳥瞰視点画像が高解像度であること
これをOpen3Dで実現する方法を検討したところ、以下のことがわかった
スクリーンショットを行うと以下のような名前のPNGとJSONが保存される。
ScreenCapture_2023-03-21-12-25-37.png ScreenCamera_2023-03-21-12-25-37.json
PNGはスクリーンショット自体で、JSONは仮想カメラの外部パラメタと内部パラメタが記録されている。 これがあれば画素の座標をそれに対応する点群の座標に変換することが可能である。(地面の高さの情報は別途必要、もしくは一緒に取得可能なDepthを用いる)
ここで実装例として以下の記事で紹介されているドローンから空撮して作成された点群を扱う。
How to visualise massive 3D point clouds in Python | Towards Data Science
通常モードの場合はスクリーンショットを取ったり、点群の表示サイズを変えるのはキーボードのキーが割当たられていて、必要なキーを押下するだけでよいのだが、 ヘッドレスレンダリングの場合は画面が表示されないのでPythonから設定の変更と表示操作を行う必要がある。 そこが少し苦労したが、実装方法がわかったのでスクリプトを公開する。
このスクリプトを実行すると以下のスクリーンショットが得られる。

$ file ortho.png ortho.png: PNG image data, 3000 x 3000, 8-bit/color RGB, non-interlace
サイズは3000x3000のPNGファイル 拡大するとわかるが、結構細部まで描画されている。 また、オルソ画像を作りたいのだが、現状はバグによりできない。詳細はコメントを参照のこと。 ヘッドレスレンダリングを有効にするための方法もコメントをい参照してほしい。
Open3DのVisualizerは他にもいくつか便利な機能を持っているので、使いこなすと色々できそうなので、また試したら記事にしようと思う。
OpenCVの魚眼カメラの表現を図解する
OpenCVは魚眼カメラの投影モデルは以下のページの「Detailed Description」で説明されている。
OpenCV: Fisheye camera model
個人的には図がないとピンとこないので、図解してみつつ何をやっているのかを確認した。
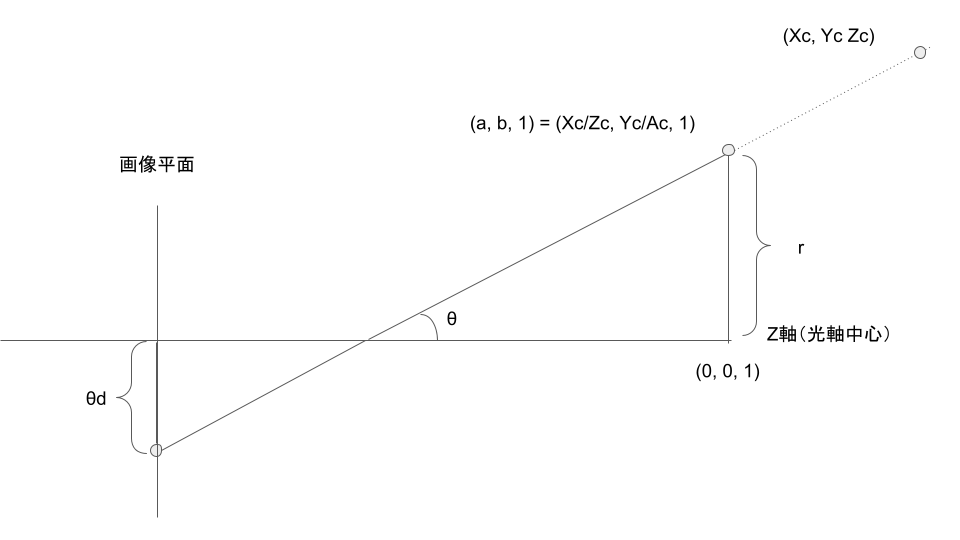
計算の流れは上記の図の右から左に向かって以下の手順で行う。
- 3Dから2Dへの投影のために、カメラ座標
を同次座標である
とおく。これは歪のない点である。
からZ軸におろした垂線の長さを
とすると
である。
- Z軸と(a, b, 1)が成す角度を
とすると
である。(90度付近の扱いはどうするんだろう)
として、
の係数で多項式近似された値を求める。(係数はキャリブレーションのときに求められたものを使う)
は
にかけて計算される。
ややこしいのはが
とは異なり、Z軸と座標点の成す角度ではなく像高であることだ。おそらく気持ち的には像高を円の弧の長さとして表現しているんだと思うけど。
とりあえず図解したことで理解が深まったので良しとする。
MVTecADのデータをPyTorchから利用するためのデータセットクラスを開発した
MVTecADという製品検査における異常検知用のデータが公開されている。
それほど扱うのが難しいデータではないが、かといってデータセットクラスの実装にはそれなりに時間がかかる。
ということでこのデータを扱うためのPyTorchのDatasetクラスを開発して公開することにした。
github.com
誰かの役に立てば幸いである。
複数画像の位置合わせによって白飛びを緩和する方法の検討
概要
光沢のある物体を撮影すると、光の反射によって一部の領域が白潰れしてしまうことがある。
撮影位置をずらしたり様々な対処法はあるが、ここでは微妙に撮影角度を変えて撮影した複数画像を使って対処する方法を考えたので共有したい。
まず扱う問題は以下のような白潰れである。

このように白飛びが起きていると、例えば画像からテキストが正しく読み取れなくなる。
試しにGCPのOCRにかけてみるとこうなる
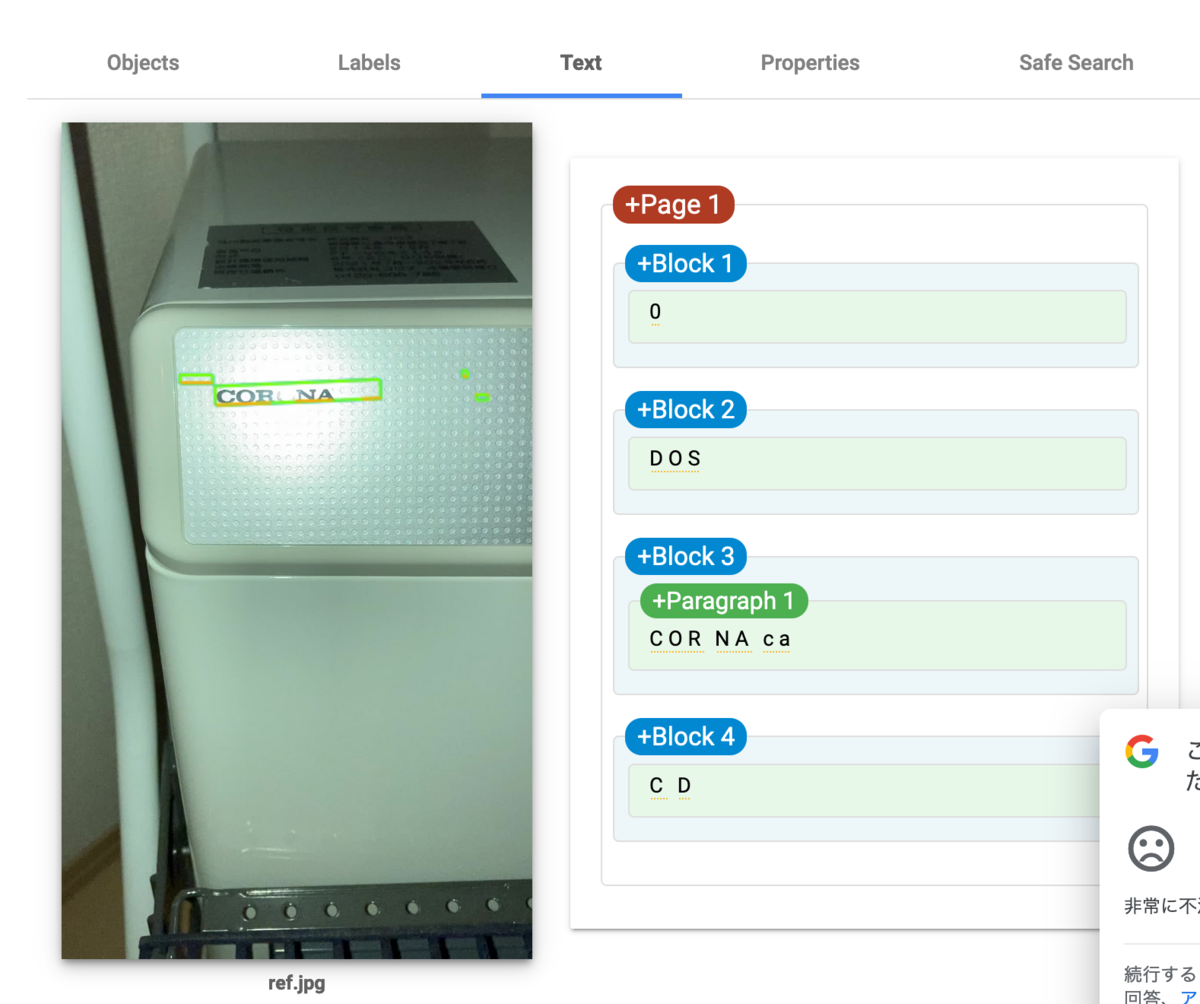
CORONAのOが読み取れていないことがわかる。
手法の詳細
考案した手法の発想は微妙に角度をずらしながら撮影すれば照明が反射する場所を少しずつ変えることができ、それらの画像を平均することで白潰れを緩和できるのではないかというものだ。
ただし、角度を変えながら撮影すると画像上の対象物の位置が変わってしまうため単純に画像の画素の平均は意味をなさない。
そのために画像の位置合わせを行うことでこれに対処する。
画像の位置合わせの手法は以下を大いに参考にさせていただいた。
qiita.com
さて全体のアルゴリズムを図示するとこのようになる。
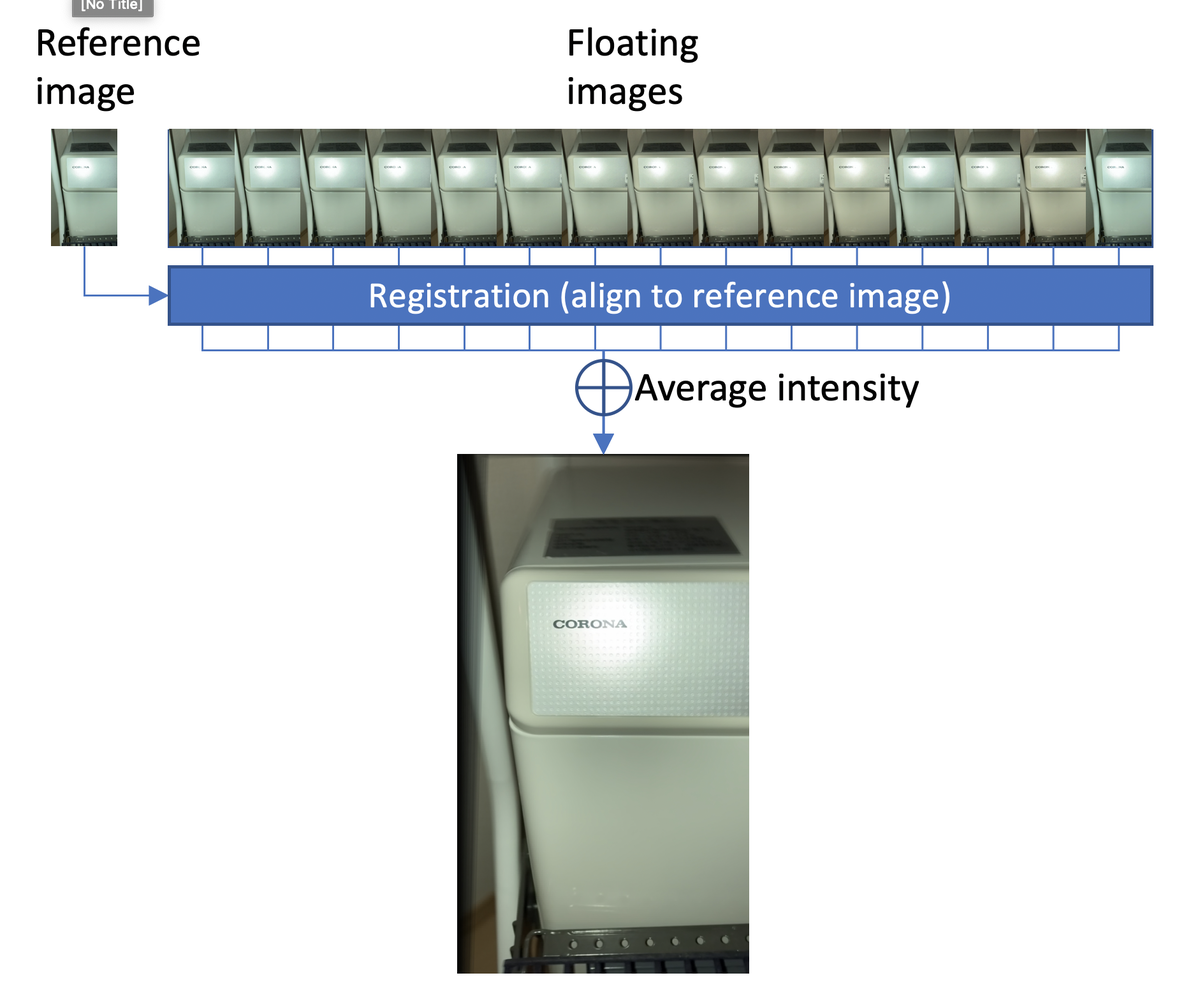
- 1ステップ目では複数枚撮った写真の中で一つを参照画像(Reference Image)とし、それ以外の画像をReference Imageに対して位置合わせする。
- 2ステップ目であh位置合わせされたすべての画像の画素値の平均をとりそれを出力とする。
非常に単純である。
ためしに先程のCORONAのストーブを撮影した下記の動画からフレームを抽出しこの手法を適用してみよう。
youtu.be
以下がその結果である。人目にCORONAがはっきり読み取れることがわかる。

次に適用前と比較する目的でGCPのOCRにこれをかけてみる。
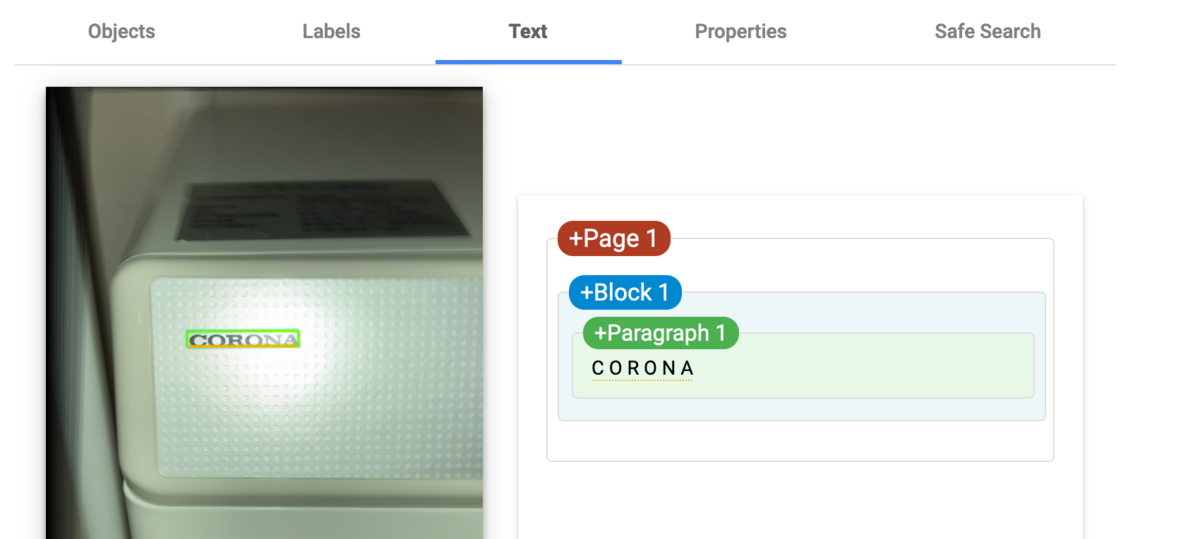
今度は正しくCORONAを読み取ることができた。
単純な手法だが、有効であることがわかった。
ソースコードはGithubに掲載した。
github.com
セイコー ダイバーズの修理(2)
前回で修理は完了したはずだったが、夜に時計を見て夜光塗料が光っていないのに気づいた。経年劣化だろう。
大した支障があるわけではないが気になるので夜光塗料を塗ってみた。
購入品
以下を購入した。夜光塗料は色々あるみたいだが、安価であり、かつアマゾンのレビューで時計修理に使用されていることがわかったのが決め手である。
Amazon.co.jp: カンペハピオ(Kanpe Hapio) 工作・ホビー用水性塗料 なし 8ML 夜光クリーム: DIY・工具・ガーデン
・光を3~5分当てることで、暗闇で15分程度発光します。
15分くらい光るなら自転車で会社から帰るときも光り続けてくれる。
修理の手順
分解
以下の手順で行う。
1. 前回同様に3点支持のオープナーを使って裏蓋を開ける。
2. 竜頭を外す
3. 時計の中身(基盤と文字版など)を引っ張り出す
1.は前回の記事と同様に行った。
2.は以下の画像に図示した箇所を爪楊枝で押しながら竜頭の取り外す
3.は時計の中身(?)を普通に爪で引っ掛けて引っ張り出す

塗装
爪楊枝の先端に少し塗料をつけて細かく塗装する。
塗料は水性なのではみ出たりしたときには剥がすことができる。
分針の塗装が非常に難しかった。縁の銀色の箇所には塗らないようにしながら白色の箇所に塗布するのだが、とにかくはみ出る。
はみ出たら爪楊枝で細かく剥がすが、剥がしすぎるとやり直しになる、ということの繰り返しだった。

実験
なんとか及第点の塗装ができたので、試しに暗い部屋で光り方を確認した。
思ったより良く光る。これはいい。

最後に
分解作業は難しくはないが、塗装がとにかく精度が求められて難しいということがわかった。正直あまり満足の行く結果は得られないことがわかった。よほど手先が器用でなければきれいに塗装することはできない。
セイコー ダイバーズの修理
実家に帰ったら父が昔着けていた時計(セイコーのダイバーズ)が放置されていた。
ゴム製のバンドがボロボロになり、電池が切れ、ペプシ柄のベゼルも傷と色あせでどうもあまり見栄えしない感じになっていた。
高級時計ではないが安い時計でもない。そこで引き取って修理することにした。
時計の修理は初めてだったが、やや苦労はありつつも問題なく修理ができた。
ここでは修理のために買ったもの、手順などを紹介したいと思う。
購入品
- ベゼルインサート 1,200円
- 時計用電池 SR43SW 195円
- SEIKO純正のバンド ウレタン 1,375円
- 腕時計工具セット1,980円
合計4,750円の出費となった。
ベゼルインサート単体をメルカリで購入した。正直これほど安く売っているものだとは思わなかった。ベゼルインサートのサイズはノギスで外周の直径(38cm)と内周(31.6)の直径を測定して同じサイズのものを検索して見つけた。ネットで探すと色や柄は各種あるようだったが、落ち着きを重視して黒の単色のものを選んだ。


電池はコンビニで探したが売ってなかった。そして検索すると時計用電池は専門店でしか売ってないようだったのでヨドバシで購入した。

バンドは無難に純正を選んだ。
修理用の工具はAmazonで適当なものを購入した。レビュー通り品質は良くないが、素人が自分の時計の修理に使う分には必要十分であった。
修理の手順
ベゼル交換
先が刃物のように鋭い道具を本体とベゼルの隙間に差し込んでテコの要領で力をかけてベゼルを外す。更にベゼルのインサートを下側から押しあげるようにして外す。(力をかけすぎるとインサートが曲がるので注意が必要。)
インサートが外れたら交換用のインサートを上から押し込む。押し込んだだけでは入り切らなないためハンマーのプラのヘッドのほうで軽く叩いてはめた。


バンド交換
古いバンドを時計から抜き取るために、バネ棒はずしを使った。
思っていたよりもバネ棒が固かったため取るのに苦労した。バネ棒外しがなかったら多分外せなかっただろうと思う。
古いバンドを取り外すよりも新しいバンドを取り付けるのは簡単だった。
電池交換
3点支持のオープナーを使って裏蓋を開ける。この3点支持オープナーの品質が悪く、ガタツキがあるため力をうまく伝えることができなかった。結局取り外すために10分以上必要だった。


裏蓋が取れると電池が見えるのだが、その上に電極と電池の固定を兼ねたパーツが覆っている。非常に小さなネジでそれは固定されているのだが、修理工具に入っていたマイナスドライバの先が厚く、そのままではネジ頭の溝に入らなかった。そこでドライバの先を包丁研ぎで数回研磨して溝に入るようにした。
しかし、ここで悲劇が起きる。この電極パーツが少しバネのようになっていて、それに気づかずドライバを回してネジを取ろうとした瞬間にネジが飛んでどっかに行ってしまったのだ。
頭が真っ白になりそうだったが、頑張って手探りで探したらなんとか見つけることができ事なきを得た。本当によかった。
最後に逆の手順で新しい電池に入れ替えたところで時計の針が動き始めた。
まとめ
時計の簡単な修理についてまとめた。
素人でもある程度の修理であればできることがわかった。
